在我们建立好深度学习模型之后,就可以使用反向传播算法进行训练了,
1.定义训练方式
在训练模型之前,我们必须使用compile方法对训练模型进行设置,指令如下:
model.compile(loss=’categorical_crossentropy’,optimizer=’adam’,metrics=[‘accuracy’])
compile方法许输入下列参数:
loss设置损失函数,在深度学习中使用cross_entropy(交叉熵)训练效果比较好.
optimizer:设置训练时,在深度学习中使用adam优化器可以让训练更快收敛,并提高准确率.
metrics:设置评估模型的方式是准确率
2.开始训练
使用model.fit进行训练,训练过程会存储在train_histroy变量中,需输入下列参数
(1)输入训练数据参数
x=x_train_normalize(featrues数字图像的特征值)
y=y_train_onehot(lacel数字图像真实值)
(2)设置参数validation_split=0.2
训练之前Keras会自动将数据分成:80%作为训练数据,20%作为验证数据.因为全部数据是60000项
所以分成:48000作为训练数据,12000作为验证数据
(3)设置epoch(训练周期)次数与每一批次项数
epochs=10:执行10个训练周期
batch_size=200:每一批次200项数据
(4)设置显示训练过程
verbose=2 显示训练过程
Train on 48000 samples, validate on 12000 samples 80%作为训练数据,20%验证数据
Epoch 1/10
– 2s – loss: 0.4413 – acc: 0.8854 – val_loss: 0.2228 – val_acc: 0.9360
Epoch 2/10
– 2s – loss: 0.1890 – acc: 0.9464 – val_loss: 0.1584 – val_acc: 0.9575
Epoch 3/10
– 2s – loss: 0.1326 – acc: 0.9620 – val_loss: 0.1260 – val_acc: 0.9643
Epoch 4/10
– 2s – loss: 0.1017 – acc: 0.9713 – val_loss: 0.1099 – val_acc: 0.9673
Epoch 5/10
– 2s – loss: 0.0811 – acc: 0.9772 – val_loss: 0.1014 – val_acc: 0.9704
Epoch 6/10
– 2s – loss: 0.0652 – acc: 0.9822 – val_loss: 0.0926 – val_acc: 0.9717
Epoch 7/10
– 2s – loss: 0.0543 – acc: 0.9852 – val_loss: 0.0837 – val_acc: 0.9747
Epoch 8/10
– 2s – loss: 0.0437 – acc: 0.9882 – val_loss: 0.0884 – val_acc: 0.9744
Epoch 9/10
– 2s – loss: 0.0372 – acc: 0.9899 – val_loss: 0.0800 – val_acc: 0.9764
Epoch 10/10
– 2s – loss: 0.0314 – acc: 0.9924 – val_loss: 0.0843 – val_acc: 0.9747
使用训练数据计算误差与准确率 使用验证数据计算误差与准确率
以上程序diamante共执行来10次训练周期,每一次训练执行下列功能:
使用48000项训练数据进行训练,分为每一批次200项,所以大约分为240个批次进行训练
训练完成后,会计算这个训练周期的准确率与误差,并且在train_history中新增一项数据记录.
从以上执行结果可知,共执行了10个周期,并可以发现误差越来越小,准确率越来越高.
3.建立show_train_history
之前的训练步骤会将每一个训练周期的准确率与误差记录在train_histroy变量中.我么可以使用下面的程序代码读取train_histroy变量中.我们可以使用下面的程序代码读取train_history,以图表显示训练过程
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title(‘Train History’)
plt.ylabel(train)
plt.xlabel(‘Epoch’)
plt.legend([‘train’,’validation’],loc=’upper left’)
plt.show()
show_train_history(train_history,’acc’,’val_acc’)
4.画出准确率执行结果
下面程序代码画出了准确率评估的执行结果,如图
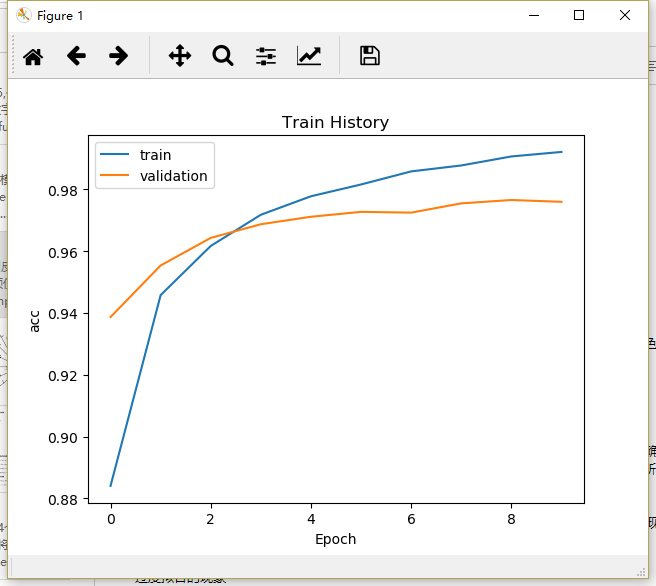
在以上执行后的屏幕显示界面中,”acc训练的准确率”是蓝色的,”val_acc”验证的准确率是黄色的,以上共执行来10个训练周期,我们可以发现:
无论是训练还是验证,准确率都越来越高
在epoch训练后期,acc训练的准确率比val_acc验证的准确率高
为何acc训练的准确率比val_acc验证的准确率高?
acc训练的准确率:以训练的数据来计算准确率,因为相同的数据已经训练过了,又拿来计算准确率,所以准确率会比较高
val_acc验证的准确率:以验证数据来计算准确率,这些验证数据在之前训练时并未拿来训练,所以计算的准确率会比较低.但是,这样计算出来的准确率比较客观,比较符合真实情况
如果acc训练的准确率一直增加,但是val_acc验证的准确率一直没有增加,可能是过度拟合的现象,从以上的图形我们可以看到,acc训练的准确率比val_acc验证的准确率高,虽然差异不是很大,但仍有轻微多度拟合的现象.
过度拟合的现象
什么是过度拟合呢?有两个分类的圆形和星形,我们希望训练后找出一条线,可以将圆形与星形进行分类,实线是我们希望找到的最佳分类线,可是训练过程太久或者范例太少会导致虚线过度适应训练数据中特化且随机的特征.
其结果是虽然在训练时准确率高,但是使用位置数据时的准确率低.
以测试数据评估模型准确率
在完成所有训练周期之后,我们还会以测试数据评估模型准确率,这是另一组独立的数据,所以计算准确率会更客观
show_train_history(train_history,’loss’,’val_loss’)
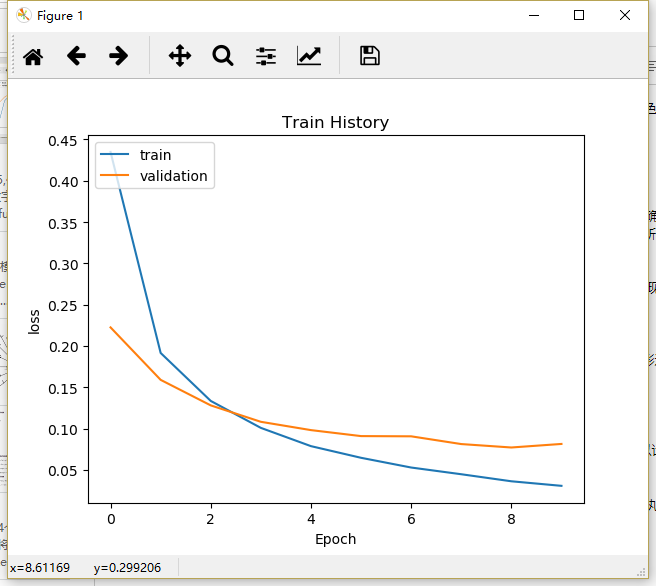
在执行结果的屏幕显示界面中,loss训练的误差是深色的,val_loss验证的误差是浅色的,总共执行来10个训练周期,我们可以发现:
无论是训练还是验证,验证的误差都越来越低
在epoch训练后期,loss训练的误差比val_loss验证的误差小