在这个例子中,我们将会估计心脏病发生的可能性,使用单变量逻辑回归,输入是患者的年龄
(1)有用的库和方法
自从版本0.8之后,TensorFlow就提供了产生one hot结果的工具
tf.one_hot(
indices,
depth,
on_value=1,
off_value=0,
axis=None,
dtype=tf.float32,
name=None
)
这种方法生成one hot编码的数据结构,可以识别数据,生成轴,数据类型等.
在输出的张量中,指示值是on_value,默认为1,其他的是off_value,默认为0.
dtype是生成的张量的数据类型,默认是float32类型
depth变量表示结果将会有多少行,我们认为他的值应该是max(indices)+1,但是也会被截取
TensorFlow中的softmax的实现使用的是tf.nn.log_softmax函数,遵循以下形式:
tf.nn.log_softmax(logits,name=None)
此处,参数如下:
logits:一个张量,格式可以为float32,float64,二维数据,形状是[batch_size,num_classes]
name:操作的名称
操作返回一个张量,类型和形状都跟logits相同
(2)数据集描述和加载
我们学习的第一个例子是拟合一个回归,输入是变量,输出只有两种可能的结果
1))CHDAGE数据集
在这个简单例子中,我们将使用一个简单的数据集,这个数据集可以绘制出年龄,冠心病是否发病.100个病人.该表格包含了身份变量(ID),年龄分段(AGEFRP).输出结果CHD,0表示没有冠心病,1表示得了冠心病.一般来说,可以用任何数值表示,但实际中,我们发现0和1最方便.我们把这个数据集称作CHDAGE数据集.
2))CHDAGE数据集格式
CHDAGE数据集是一个二列CSV文件,我们可以从一个外部仓库下载
之前我们使用了TensorFlow自带的方法来读取该数据集,在本例中,我们将会用另外一个非常流行的库来读取该数据集.
这样做的原因是,该数据集有100个元组,最好能够将他们用一行代码读入,我们拥有简单而强大的免费工具,由pandas提供.
在本工程的初始阶段,我们加载CHDAGE数据集,打印出重要的统计量,然后进行预处理
在打印出数据之后,我们建立一个带激活函数的模型,激活函数选择softmax函数,在二类的时候,这就是一个logistic函数;这就是只有两类的时候
3))数据集加载和预处理实现
首先,我们引入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
我们使用pandas库来读取数据,检查数据集的统计信息
df = pd.read_csv(“data/CHD.csv”, header=0)
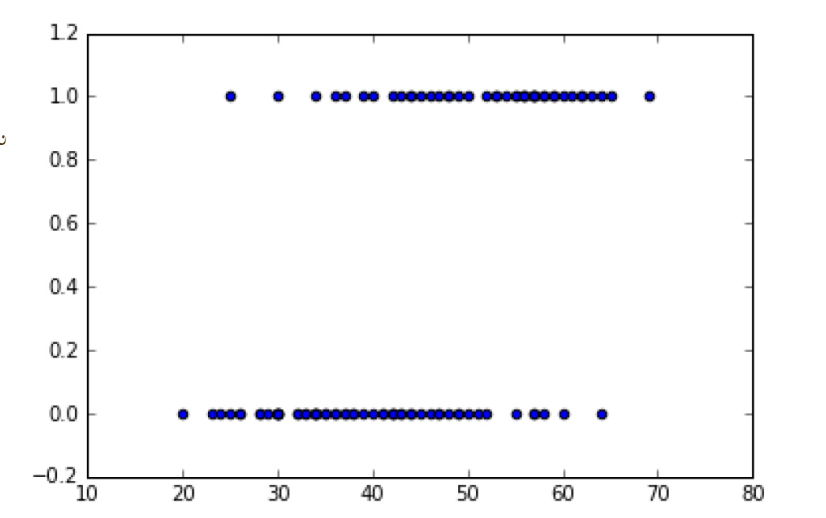
然后处理数据,并绘制数据,使得我们对数据有大致的了解
plt.figure()
plt.scatter(df.[‘age’],df[‘chd’])
结果如下图:
(3)模型结构
此处,我们将会描述如何建立该模型
learning_rate = 0.2
batch_size = 100
display_step = 1
此处,我们为数据流图创建初始变量和占位符.但变量x和y都是浮点类型变量.
x = tf.placeholder(“float”, [None, 1])
y = tf.placeholder(“float”, [None, 2])
现在,我们创建线性模型,他们在模型被拟合的过程中将会不断变化
W = tf.Variable(tf.zeros([1, 2]))
b = tf.Variable(tf.zeros([2]))
最后,我们创建激活函数,并且将其作用于线性方程之上
activation = tf.nn.softmax(tf.matmul(x, W) + b)
(4)损失函数描述和优化器循环
此处,我们定义交叉相关函数为损失函数,定义优化器操作,选择梯度下降.这将会在后续章节中展开,现在我们把它当作一个黑盒,使他最小化
# Minimize error using cross entropy
cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(activation), reduction_indices=1)) # Cross entropy
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) # Gradient Descent
…
(5)停止条件
带迭代次数满足的时候,程序停止