kafka自带了对连接器应用的脚本,用于将外部系统导入到kafka或从kafka中导出到外部系统,kafka连接器有独立模式(standalone)和分布式模式(distributed)两种工作模式。kafka自带脚本connect-standalone.sh和connect-distrubuted.sh分别对应kafka连接器的两种工作模式,本节将根据kafka提供的连接器执行脚本分别介绍在这两种工作模式下kafka与外部系统之间数据交互的操作。
1.独立模式
kafka自带脚本connect-standalone.sh用于以独立模式启动kafka连接器,本小节将介绍如何通过该脚本将文件中的数据导入到kafka以及将kafka中的数据导出到文件
执行该脚本时需要指定两个配置文件,一个时worker运行时相关配置的配置文件,成为workConfig,在该文件中指定与kafka建立连接的配置(bootstrap.servers)、数据格式转换类(key.converter/value.converter)、保存偏移量的文件路径(offset.storage.file.filename)、提交偏移量的频率(offset.flush.interval.ms)等,另外一个时指定source连接器或是sink连接器配置的文件,可同时指定多个连接器配置,每个连接器配置文件对应一个连接器,因此要保证连接器名称全局唯一,连接器名通过name属性指定。
(1)source连接器
source连接器用于将外部数据导入到kafka相应主题中,kafka自带的connect-file-source.properties文件配置了一个读取文件的source连接器,修改配置文件内容:
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=/root/test.txt
topic=connect-test-single
|
属性名
|
属性描述
|
|
name
|
连接器名称
|
|
connector.class
|
source连接器执行类,该类继承org.apache.kafka.connect.source.SourceConnector类
|
|
tasks.max
|
SourceTask数量
|
|
file
|
该连接器数据源文件路径
|
|
topic
|
数据导入的目标主题名称
|
在启动连接器之前,先在/root/test.txt目录下创建一个test.txt文件,然后执行以下命令启动一个从文件导入数据到kafka的连接器:
./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-source.properties
该命令支持daemon参数,以daemon方式启动的命令如下:
./connect-standalone.sh -deamon ../config/connect-standalone.properties ../config/connect-file-source.properties
登录zookeeper客户端,查看主题元数据信息:
./zkCli.sh -server node1:2181
[zk: node1:2181(CONNECTED) 4] get /brokers/topics/connect-test-single/partitions/0/state
{“controller_epoch”:5,”leader”:2,”version”:1,”leader_epoch”:0,”isr”:[2]}
cZxid = 0xc00000085
ctime = Thu Mar 21 23:09:33 EDT 2019
mZxid = 0xc00000085
mtime = Thu Mar 21 23:09:33 EDT 2019
pZxid = 0xc00000085
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 72
numChildren = 0
由主题元数据可知,当启动一个source连接器后,发送消息时会通过生产者创建主题的方式创建一个source连接器启动时指定的主题(若主题不存在),该主题拥有一个分区,该分区被分配到brokerId为2的节点上,在该节点执行以下命令,查看分区中导入的数据:
[root@kafka2 bin]# ./kafka-run-class.sh kafka.tools.DumpLogSegments –files /tmp/kafka-logs/connect-test-single-0/00000000000000000000.log –print-data-log
该命令执行后输出结果:
Dumping /tmp/kafka-logs/connect-test-single-0/00000000000000000000.log
Starting offset: 0
offset: 0 position: 0 CreateTime: 1553224701550 isvalid: true keysize: -1 valuesize: 61 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: {“schema”:{“type”:”string”,”optional”:false},”payload”:”111″}
offset: 1 position: 0 CreateTime: 1553224701551 isvalid: true keysize: -1 valuesize: 62 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: {“schema”:{“type”:”string”,”optional”:false},”payload”:”aaaa”}
offset: 2 position: 200 CreateTime: 1553224729627 isvalid: true keysize: -1 valuesize: 61 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: {“schema”:{“type”:”string”,”optional”:false},”payload”:”aaa”}
(2)sink连接器
kafka自带脚本connect-console-sink.properties配置了一个将kafka中的数据导出到文件的sink连接器,这里将该配置文件稍微进行修改,指定数据导出路径为/root/output.txt,各sink连接器的配置说明如下表所示:
|
属性名
|
属性描述
|
|
name
|
连接器名称
|
|
connector.class
|
sink连接器执行类,该类继承org.apache.kafka.connect.sink.sinkConnector类
|
|
tasks.max
|
sinkTask数量
|
|
file
|
数据导出后输出的目标文件路径
|
|
topics
|
导出数据源对应的主题名称,可指定多个主题
|
执行以下命令,启动sink连接器,将上一小节导入到kafka的数据导出到/root/output.txt中
./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-sink.properties
sink连接器是通过kafkaConsumer从指定的主题中消费消息,在Sink连接器启动日志中会看到加载ConsumerConfig的配置信息,在启动Sink连接器时可以在WorkConfig配置文件中以“consumer”为前缀来指定Consumer级别的配置,本小节介绍的FileStreamSink连接器,默认情况下是以Sink连接器名作为group.id的,且不同连接要求全局唯一,也就是说,默认情况下不同的连接器属于不同消费组
可以同时启动多个sink连接器,将connect-file-sink.properties文件复制一份命名为connect-file-sink-2.properties,同时修改文件内容如下所示:
name=local-file-sink-2
connector.class=FileStreamSink
tasks.max=1
file=/root/output-2.txt
topics=connect-test-single
2.REST风格API应用
kafka提供了一套基于REST风格API接口来管理连接器,默认端口为8083,也可以在启动kafka连接器前在WorkConfig配置文件中通过rest.port配置端口,相关REST风格接口在Kafka.connect源码runtime工程的org.apache.kafka.connect.runtime.rest.resources包下定义,相关的REST风格接口说明如下表所示:
|
接口URL
|
访问方式
|
接口说明
|
|
/
|
GET
|
查看kafka版本信息
|
|
/connectors
|
GET
|
查看当前活跃的连接器列表,显示连接器名称
|
|
/connectors
|
POST
|
根据指定配置,创建一个新连接器
|
|
/connectors/{connector}
|
GET
|
查看指定连接器的信息
|
|
/connectors/{connector}/config
|
GET
|
查看指定连接器的配置信息
|
|
/connectors/{connector}/config
|
PUT
|
修改指定连接器的配置
|
|
/connectors/{connector}/status
|
GET
|
查看指定连接器的状态
|
|
/connectors/{connector}/restart
|
POST
|
重启指定连接器
|
|
/connectors/{connector}/pause
|
PUT
|
暂停指定连接器
|
|
/connectors/{connector}/resume
|
PUT
|
恢复所指定的被暂停的连接器
|
|
/connectors/{connector}/tasks
|
GET
|
查看指定连接器正在运行的Task
|
|
/connectors/{connector}/tasks
|
POST
|
修改Task配置,即覆盖现有Task,只支持分布模式
|
|
/connectors/{connector}/tasks/{task}/status
|
GET
|
查看某个连接器的某个Task的状态
|
|
/connectors/{connector}/tasks/{task}/restart
|
POST
|
重启某个连接器的某个task
|
|
/connectors/{connector}
|
DELETE
|
删除指定连接器
|
|
/connectors-plugins
|
GET
|
查看已配置的连接器,显示连接器实例的完整路径
|
|
/connectors-plugins/{connectorType}/config/validate
|
PUT
|
验证指定的配置,返回各配置
|
(1)获取config信息
首先设置HTTP请求方式为GET,同时设置HTTP的header信息,在postman的header界面配置以下HTTP信息:
请求获得配置信息如下:
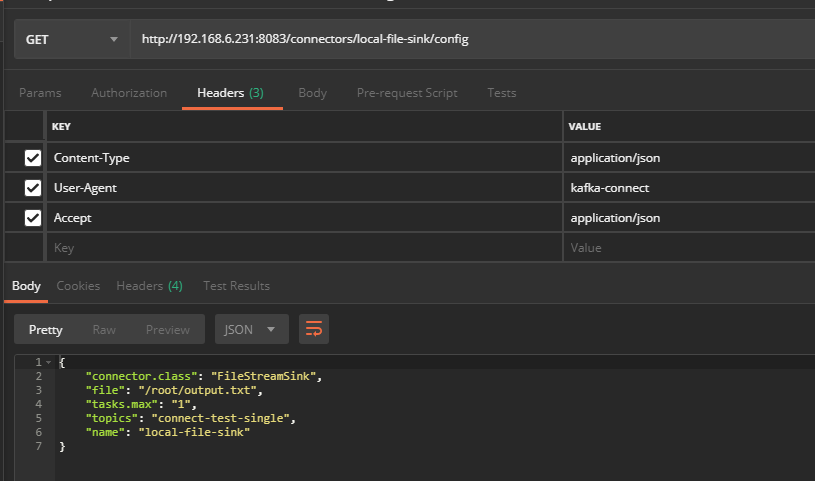
(2)重启连接器
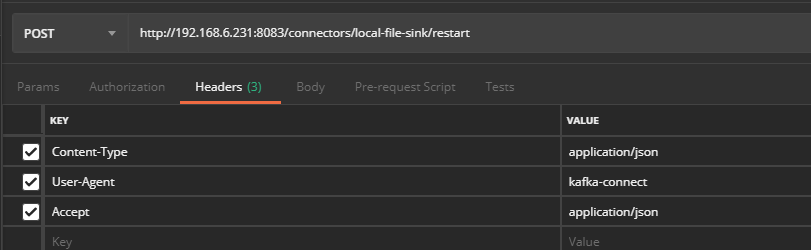
由于是重启操作,所以该接口调用并不会返回操作相应结果,通过查看连接器运行日志可看到该接口返回应答信息如下所示:
[2019-03-22 08:44:01,218] INFO 192.168.6.91 – – [22/Mar/2019:12:44:01 +0000] “POST /connectors/local-file-sink/restart HTTP/1.1” 204 0 16 (org.apache.kafka.connect.runtime.rest.RestServer:60)
3.分布式模式
kafka自带的connect-distributed.sh脚本用于以分布式模式运行连接器,执行该脚本时需要指定一个workConfig类型的配置文件,当以分布式模式启动连接器并不支持在启动时加载连接器配置文件创建一个连接器,而只能通过访问REST风格接口创建连接器
以分布式模式启动连接器时,通常需要关注如下表所示的配置项:
|
属性名
|
属性描述
|
|
group.id
|
连接器cluster的唯一标识
|
|
boostrap.servers
|
与kafka代理建立连接配置
|
|
config.storage.topic
|
用于存储连接器相关配置信息的主题,包括创建连接的配置信息以及连接的Task信息,要指定该主题拥有一个分区和多个副本,需要手动创建
|
|
offset.storage.topic
|
用于存储source连接器读取数据对应偏移量的主题,与存储消费者提交的内部主题作用相同。该主题通常有多个分区和多个副本,若kafka启动时指定auto.create.topics.enable=true,则根据默认分区数自动创建该主题,因此建议该主题也通过手动创建
|
|
status.storage.topic
|
用于存储连接器每个task状态的主题,该主题通常也有多个分区和多个副本,也需要手动创建
|
|
session.timeout.ms
|
用于设置连接器的work与workCoordinator之间的最大超时时间,work会周期性的向WorkCoordinator发送心跳,让workCoordinator以此来判断work是否有效,若在配置时间内还未收到Work发送的心跳则WorkCoordinator会将该work从工作组移除,同时触发WorkCoordinator进行平衡操作
|
|
offset.flush.intval.ms
|
连接器task提交偏移量的时间间隔
|
|
heartBeat.interval.ms
|
连接器work向workCoodinator发送心跳检测的间隔时间,推荐该值不超过session.timeout.ms的1/3
|
在对连接器分布式模式运行的配置了解之后,按以下步骤运行kafka自带的FileStream Source连接器和FileStreamSink连接器
(1)修改WorkConfig配置文件。修改${KAFKA_HOME}/config目录下的connect-distributed.properties文件,这里仅进行以下修改:
bootstrap.servers=kafka1:9092,kafka2:9092,kafka3:9092
(2)创建相关主题。依次创建connect-distributed.properties文件中配置的3个主题
(a)创建保存偏移量的主题,命令如下:
[root@kafka1 bin]# ./kafka-topics.sh –create –zookeeper node1:2181,node2:2181,node3:2181 –replication-factor 2 –partitions 3 –topic connect-offsets
Created topic “connect-offsets”.
(b)创建保存连接器配置的主题,命令如下:
[root@kafka1 bin]# ./kafka-topics.sh –create –zookeeper node1:2181,node2:2181,node3:2181 –replication-factor 2 –partitions 1 –topic connect-configs
Created topic “connect-configs”.
(c)创建保存Task状态的主题,命令如下:
[root@kafka1 bin]# ./kafka-topics.sh –create –zookeeper node1:2181,node2:2181,node3:2181 –replication-factor 2 –partitions 3 –topic connect-status
Created topic “connect-status”.
(3)分布式模式启动
执行connect-distributed脚本,以分布式模式启动连接器,执行命令如下:
[root@kafka1 bin]# ./connect-distributed.sh ../config/connect-distributed.properties
(4)创建一个FileStreamSource连接器,首先在/root/目录下创建一个名为connect-distributed.txt的文件,然后编辑创建FileStreamSource连接器的相关配置,配置内容如下所示,我们指定该连接器将/root/connect-distributed.txt文件中的数据导入一个名为connect-distributed的主题,数据转化类为org.apache.kafka.connect.storage.StringConverter.
{
“name”:”local-file-distribute-source”,
“config”:{
“topic”:”connect-distributed”,
“connector.class”:”FileStreamSource”,
“file”:”/root/connect-distributed.txt”,
“key.converter”:”org.apache.kafka.connect.storage.StringConverter”,
“value.converter”:”org.apache.kafka.connect.storage.StringConverter”,
“converter.internal.key.converter”:”org.apache.kafka.connect.storage.StringConverter”,
“converter.internal.value.converter”:”org.apache.kafka.connect.storage.StringConverter”
}
}
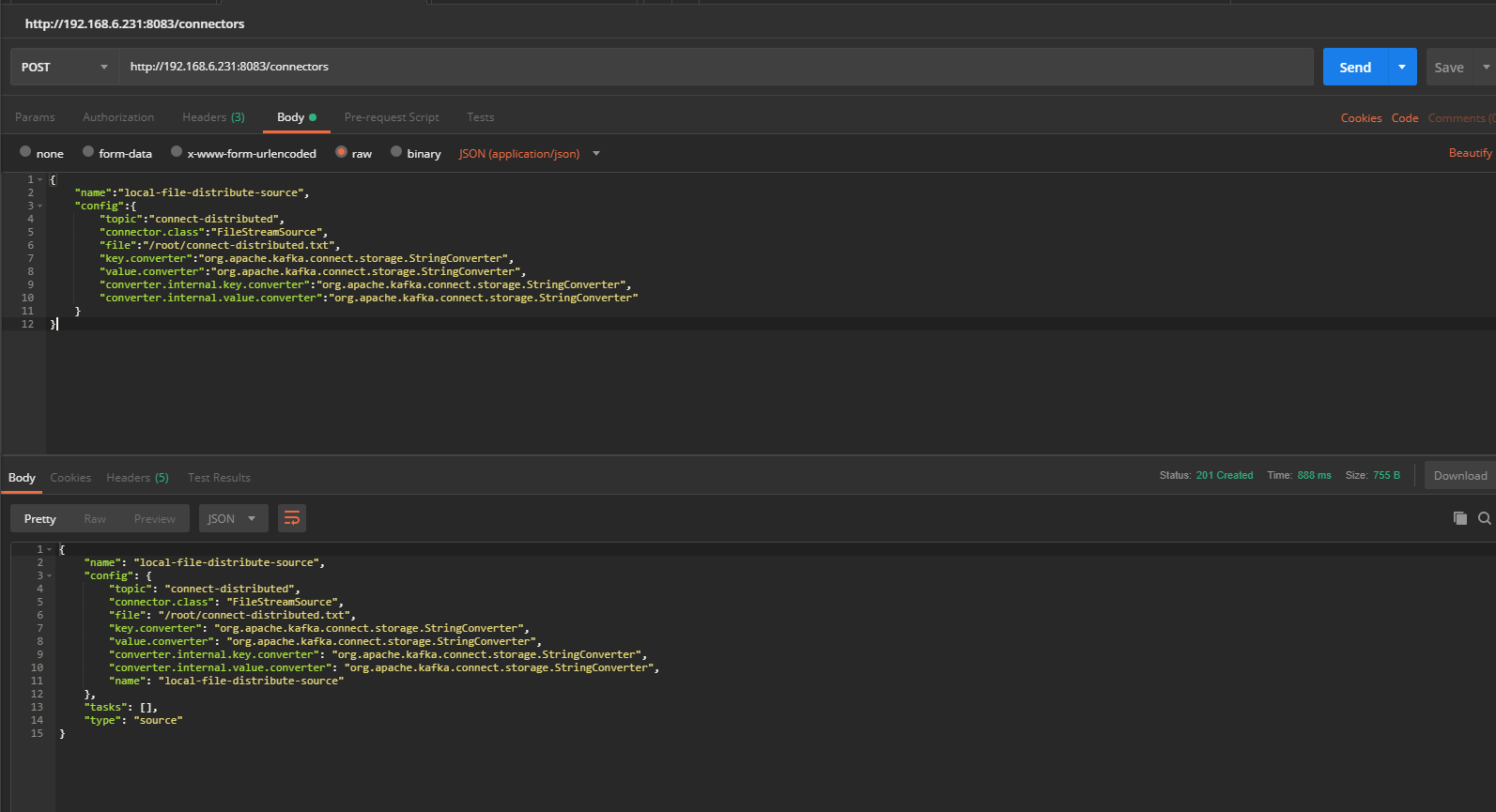
待创建连接器的请求成功返回后,通过REST风格接口查看该连接器的信息,在postman中访问REST风格接口请求查看该连接器的信息设置及响应结果如图所示:
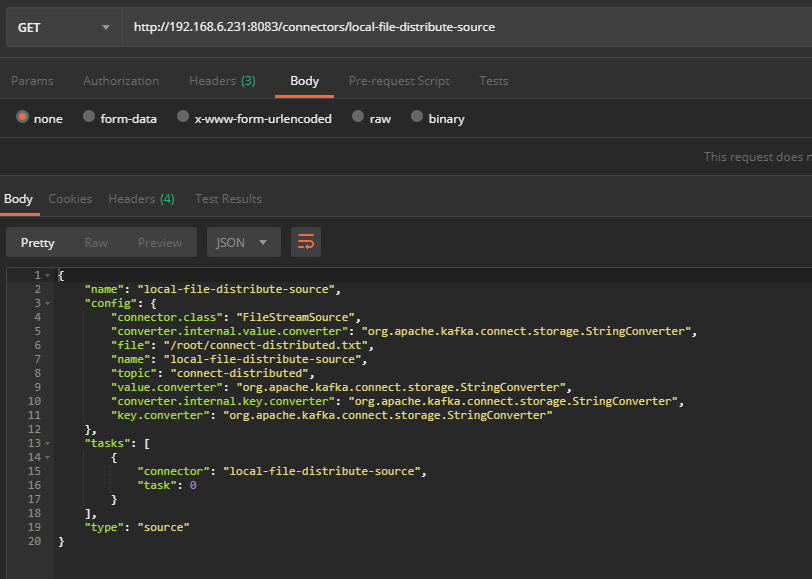
然后向/root/connect-distributed.txt发送数据,验证FileStreamSource连接器是否正常运行
[root@kafka1 config]# echo ‘connect-distributed’ >> /root/connect-distributed.txt
此时,登录zookeeper客户端,查看目标主题“connect-distributed”是否被创建以及该主题分区对应的节点信息:
[zk: node1:2181.node2:2181,node3:2181(CONNECTED) 1] get /brokers/topics/connect-distributed/partitions/0/state
{“controller_epoch”:6,”leader”:3,”version”:1,”leader_epoch”:0,”isr”:[3]}
cZxid = 0xd000000f2
ctime = Fri Mar 29 02:15:29 EDT 2019
mZxid = 0xd000000f2
mtime = Fri Mar 29 02:15:29 EDT 2019
pZxid = 0xd000000f2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 72
numChildren = 0
登录分区对应的节点,查看导入的数据,执行命令如下:
[root@kafka3 bin]# ./kafka-run-class.sh kafka.tools.DumpLogSegments –files /tmp/kafka-logs/connect-distributed-0/00000000000000000000.log –print-data-log
Dumping /tmp/kafka-logs/connect-distributed-0/00000000000000000000.log
Starting offset: 0
offset: 0 position: 0 CreateTime: 1553840129632 isvalid: true keysize: -1 valuesize: 19 magic: 2 compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: [] payload: connect-distributed
至此,FileStreamSource连接器已正常运行
(5)创建一个FileStreamSink连接器
通过REST风格接口创建一个FileStreamSink连接将第4步导入的数据导出到connect-distributed-sink.txt文件中,创建该连接器的配置如下所示,对应的connector.class为FileStreamSink,通过topics参数指定数据源主题:
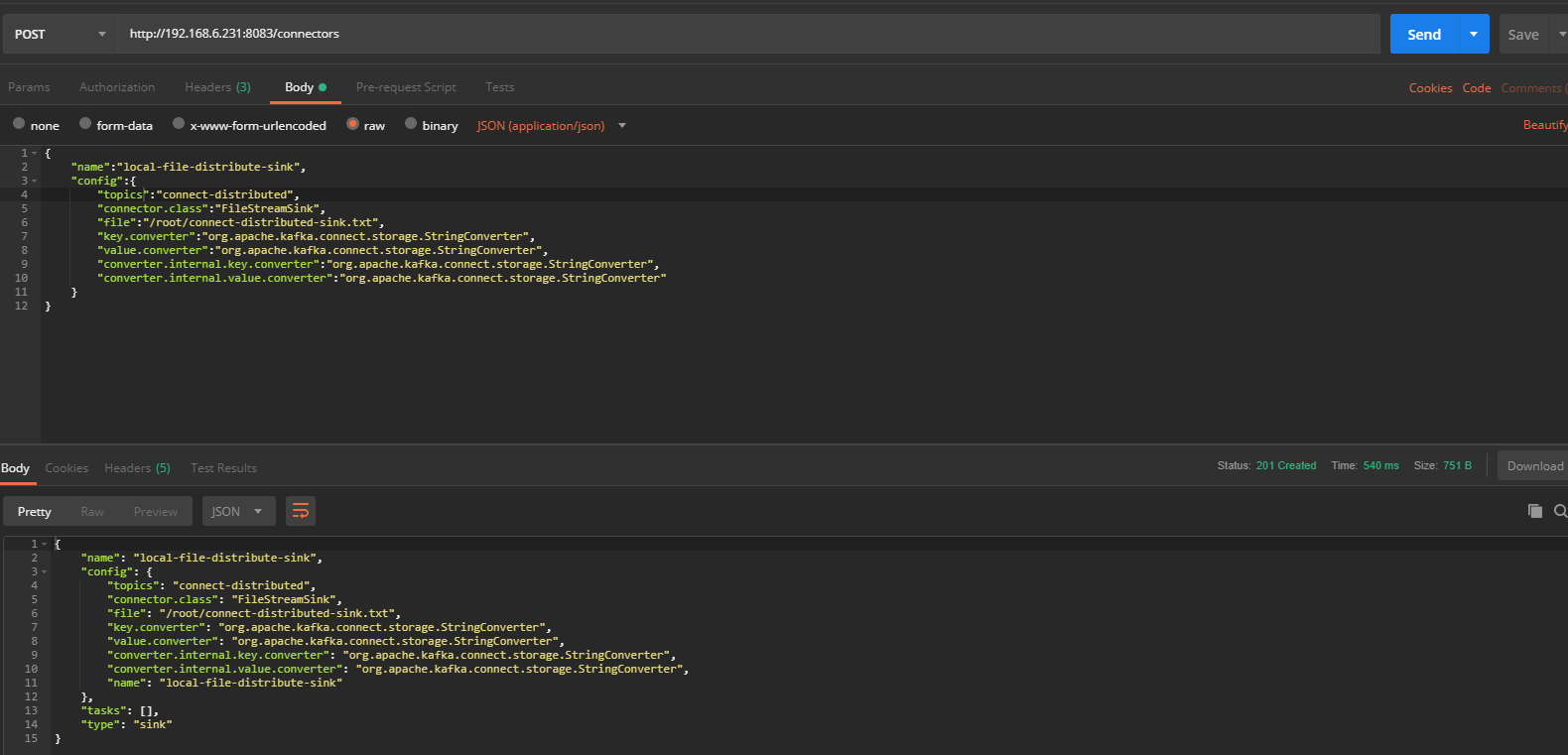
查看当前活跃的连接器信息如下图所示:
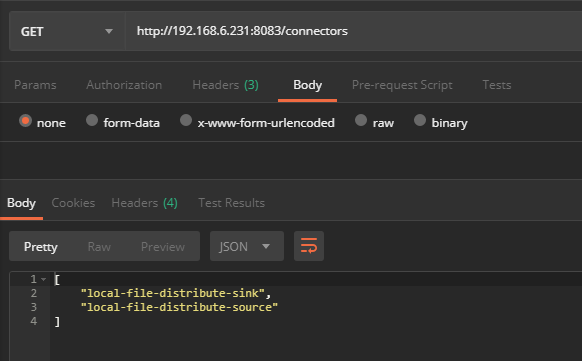
打开文件,可以看到导入到kafka中的数据已被成功导出:
[root@kafka1 config]# cat /root/connect-distributed-sink.txt
connect-distributed