先简要介绍kafka延迟操作组件,该组件可以辅助kafka其他组件完成相应的功能,如协助客户端处理创建主题操作,协助组协调器(GroupCoordinator)处理JoinGroupRequest和HeartbeatRequst请求,协助副本管理器处理ProduceReqest和FetchRequest请求,因此在讲解kafka其他组件之间,先介绍kafka的延迟操作组件
(1)delayOperation
kafka将一些不立即执行而要等待一定条件之后才触发完成的操作称为延迟操作,并将这类操作定义为一个抽象类DelayedOperation,DelayedOperation是一个基于事件启动有失效时间的TimerTask,TimeTask实现了Runnable接口,维护了一个TimeTaskEntry对象,TimeTaskEntry绑定了一个TimerTask,TimerTaskEntry被添加到TimerTaskList,TimerTaskList是一个环形双向链表,按失效时间排序.
DelayedOperation是一个抽象类,具体的延迟操作类继承于该抽象类,分别用来协助相应组件对不同的请求完成延迟处理操作,类图如图所示
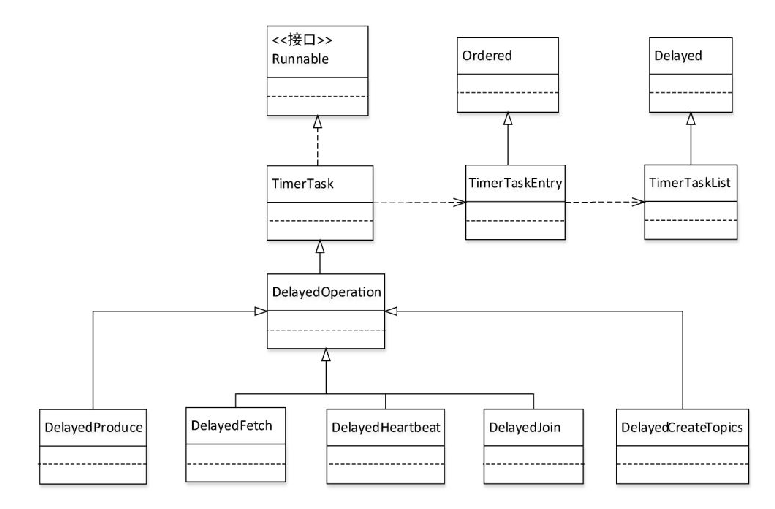
DelayedOperation只有一个AtomicBoolean类型的completed属性,用来控制某个延迟操作,在延迟时间(delayMs)内,onComplete()方法只被调用一次,DelayedOperation的主要方法如下:
tryComplete()方法:一个抽象方法,由子类实现,负责检测执行条件是否满足,若满足执行条件,则调用forceComplete()方法完成延迟操作
forceComplete()方法:该方法在条件满足时,检测延迟任务是否被执行,若未被执行,则先调用TimerTask.cancel()方法解除该延迟操作与TimerTaskEntry的绑定,将该延迟操作从TimerTaskList链表中移除,然后调用onComplete()方法让延迟操作执行完成.通过completed的CAS原子操作(completed.compareAndSet),可以保证并发操作时只有第一个调用该方法的线程能够顺利调用onComplete()完成延迟操作,其他线程获取的completed属性为false,即不会调用onComplete()方法,这就保证onComplate()只会被调用一次
onComplete()方法:是一个抽象方法,由子类来实现,执行延迟操作满足执行条件后需要执行的实际业务逻辑,例如,DelayedProduce和DelayedFetch都是在该方法内调用responseCallback向客户端做出响应
safeTryComplete()方法:以synchronized同步锁调用onComplete()方法,供外部调用
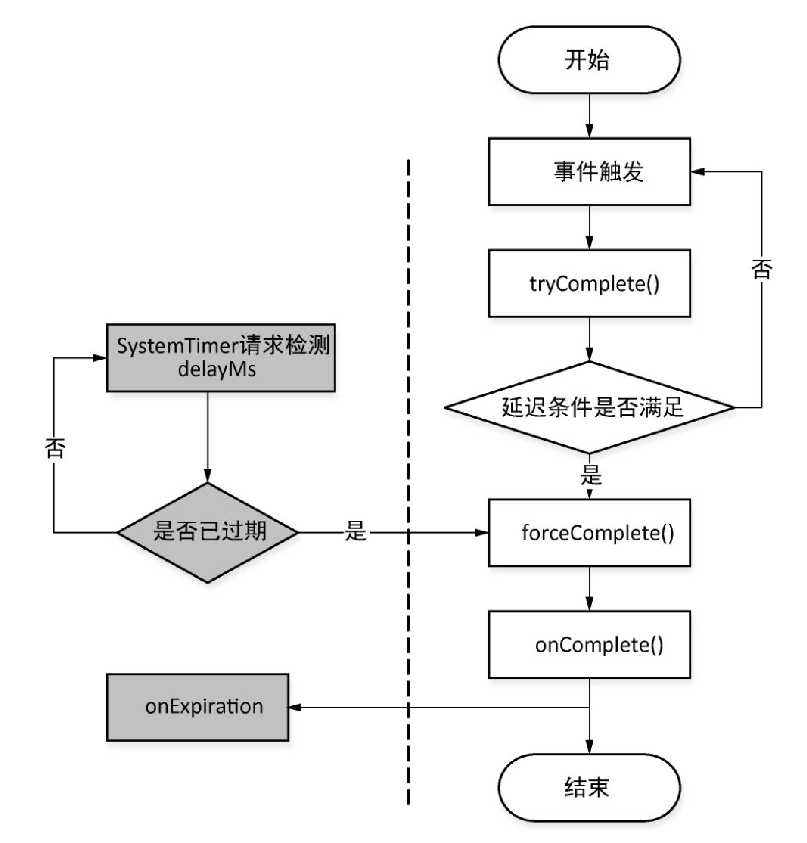
onExpiration()方法:也是一个抽象方法,由子类来实现当延迟操作已达失效时间的相应逻辑处理,kafka通过SystemTimer来定期检测请求是否超时.SystemTimer是kafka实现的底层基于层级时间轮和delayQueue定时器,维护了一个newFixedThreadPool线程池,用于提交相应的线程执行.例如,当检测到延迟操作已失效时则将延迟操作提交到该线程池,即执行线程的run()方法的逻辑.delayedOperation覆盖了TimerTask的run()方法,在该方法中先调用forceCompete()方法,当该方法返回true后再调用onExpiration()方法,对于SystemTimer的实现细节,就不进行阐述了.
kafka当前的设计onComplete()方法是向客户端做出响应的唯一出口,当延迟操作达到失效时间时也是先执行forceCompete(),让onComplete()方法执行之后再调用onExpiration()方法,在onExpiration()方法中仅是进行相应的过期信息手机子类的操作.DelayedOperation各方法在一个延迟周期内的调用关系如图所示:
(2)DelayedOperationPurgatory
DelayedOperationPurgatory是一个对DelayedOperation管理类的辅助类,为了书写简便,我们将其称为purgatory,purgatory以泛型的形式将一个DelayedOperation添加到其内部维护的pool[any,watchers]类型watchersForKey对象中,同时将DelayedOperation添加到SystemTimer中.
其中,watchers是Purgatory的内部类,底层是一个ConsurrentLinkedQueue,该类定义了一个ConsurrentLinkedQueue类型的operations属性,用于保存DelayedOperation,从Watchers类型可以看出,该类的作用就是对DelayedOperation进行监视,watchers提供了以下3个对DelayedOperation操作的方法:
watch()方法:用于将delayedOperation添加到operations集合中
tryCompleteWatched()方法:用于迭代operations集合中的DelayedOperation,通过DelayedOperation.isCompleted检测该DelayedOperation是否已执行完成.若已执行完成,这从Operations集合中移除该DelayedOperation.是否调用DelayedOperation.safeTryComplete()方法尝试让该DelayedOperation执行完成.若执行完成,即safeTryComplete()返回true,则将该DelayedOperation从operations集合中移除,最后检测operations集合是否为空,如果operations为空,这表示该operations所关联的DelayedOperation已全部执行完成,因此将该Watchers从Purgatory的Pool中移除
purgeCompleted()方法:与tryComplateWatched()方法基本功能类似,区别在于purgeComplated()方法只单纯的将该operations集合中已完成的DelayedOperation移除,对未完成的DelayedOperation并不尝试将其执行完成
我们可以简单的将Purgatory与Spring Quartz类比,这样对Purgatory的作用就不难理解了,Purgatory相当于Quartz的SchedulerFactoryBean,而DelayedOperation相当于ScheduleFactoryBean所管理的具体Schedule,由Purgatory负责调度,只不过Purgatory除了管理调度DelayedOperation之外,还负责DelayedOperation超时的管理.下面简要介绍Purgatory的两个主要方法:
tryCompleteEleWatch()方法:该方法首先调用待检测的DelayedOperation.safeTryComplete()方法,检测是否能执行完成,若未执行完成,这迭代watchersForKey对应的DelayedOperation检测DelayedOperation是否已完成,若未完成,则将其添加到Watchers中,添加完成后再调用safeTryComplete()方法再次尝试让DelayedOperation执行完成,若还是未完成,再将其添加到System.Timer中,添加完后再次检测是否执行完成,若已执行完成则将其从System.timer中移除,可以看到,在这个操作逻辑中多次执行safeTryComplete()方法以及多次检测是否已完成,是以防在操作过程中可能已被其他线程触发执行完成,同时将DelayedOperation添加到Watchers操作时并没有将原来的Key清理掉,这是因为Purgatory在启动时会同时启动一个ExpiredOperationReaper线程,该线程除了推进时间轮的指针外还会定期清理watchersForKey已完成的DelayedOperation
checkAndComplete()方法:根据传入的key,检测该key对应的watchers是否执行完成,若未完成,再调用watchers.tryCompleteWatched()方法进行处理
由此可见,Purgatory对DelayedOperation的管理是通过Watchers来完成的,通过Watchers调用DelayedOperation相应的方法,让DelayedOperation要么在delayMS时间内完成,要么超时.在对Purgatory有了基本了解之后,下面将逐一介绍DelayedOperation实现类的具体作用及实现细节
(3)DelayedProduce
我们从DelayedProduce的构造方法参数开始一步一步深入,对DelayedProduce的作用和实现细节进行讲解:
DelayedProduce(
delayMS:Long,
ProduceMetadata:ReplicaManager,
replicaManager:ReplicaManager,
responseCallback:Map[TopicPartition,PartitiionResponse]=>Unit
)
由构造方法的参数可知,DelayedProduce是协助ReplicaManager完成相应延迟操作的,而ReplicaManager的主要功能是负责将生产者发送的消息写入Leader副本,管理Follower副本与Leader副本之间的同步以及副本角色之间的转换,DelayedProduce显然是与生产者发送消息相关的延迟操作,因此只可能在消息写入Leader副本时需要DelayedProduce的协助,在ReplicaManager.appendMessages()方法中,当ProduceRequest的acks为-1的情况下,创建了一个DelayedProduce对象,当生产者调用KafkaProducer.appendMessages()方法将消息追加到相应分区的Leader副本之中,produceRequest的acks为-1.意味着生产者需要等待该分区的所有副本都与Leader副本同步之后才会进行下一条信息的发送.若要控制在分区各Follower副本与Leader副本同步完成后再向生产者应答,就要发挥DelayedProduce的作用了
由以上分析可知,DelayedProduce的作用就是协助副本管理器在acks为-1的场景时,延迟回调responseCallback向生产者做出响应,具体表现在当消息追加到分区Leader副本之后,该分区各Follower副本完成了与Leader副本消息同步之后再回调responseCallback给生产者
DelayedProduce继承DelayedOperation类,因此必须实现DelayedOperation类两个抽象方法,在分析DelayedProduce实现这两个抽象方法之前,我们对DelayedProduce构造方法的其他几个参数进行简单介绍.参数delayMS指延迟时间,参数productMetadata是一个productMetadata对象,记录了本次ProductRequest的ack信息即produceRequiredAcks,以及对应分区对消息追加处理结果信息ProducePartitionStatus,producePartitionStatus对象包括本次追加消息的最大片力量requiredOffset,分区处理结果PartitionResponse以及一个用于标识是否还在进行数据同步的Boolean类型的acksPending字段,当副本同步完成后此字段为false,PartitiionResponse对象由处理的结果码errorCode,消息写入日志段的基准偏移量baseOffset和消息追加的时间戳timestamp组成,在初始化时,PartitionResponse.errorCode为Errors.REQUEST_TIMED_OUT.code
DelayedProduce能够执行的条件及处理逻辑如下
(1)写操作发生异常,更新该分区的ProducePartitiionStatus.PartitiionResponse.errorCode,同时更新acksPending=false
(2)当分区Leader副本发生迁移时,此时也需要更新该分区的ProducePartitionStatus和acksPending=false
(3)ISR副本同步完成,Leader副本的HW已大于requiredOffset,通过Partition.checkEnoughReplicasReachOffset处理后会修改DelayedProduce初始化时对PartitionResponse.errorCode所设置的默认值
DelayedProduce.tryComplete()方法检测DelayedProduce是否满足执行条件,DelayedProduce需要在本次请求对应的所有分区都满足条件之后才调用forceComplete()方法来完成延迟操作
延迟操作满足执行条件后需要执行的业务逻辑是由onComplete()方法处理,因此DelayedProduce的onComplete()方法就是回调respoonseCallback向客户端做出响应
(4)DelayedFetch
DelayedProduce是在ProduceRequest处理中对生产者发送消息的延迟操作,自然DelayedFetch就是FetchRequest处理时进行的延迟操作,在kafka中只有消费者或是follower副本会发起FetchRequest请求,fecthRequest是由kafkaApis.handleFetchRequest()方法处理的,在该方法中会调用ReplicaManager.fetchMessages()方法从响应分区的Leader副本拉取消息,在ReplicaManager.fetchMessages()方法中会创建DelayedFetch延迟操作
DelayedFetch构造方法有一个fetchMetadata参数,该参数是一个FetchMetadata对象,该对象包括指定本次拉取操作获取数据的最小即最大字节数字段,是否自从Leader副本读取以及是否只读HW之前的数据的标志字段,一个用来标识是消费者还是Follower副本的replicaId字段,用来记录本次从每个分区拉取结果的fetchPartitionsStatus字段,从FetchMetadata对象的字段也可以看出之所以在拉取消息时需要延迟操作,是为了让本次拉取消息获取到足够的数据.
DelayedFetch若满足以下条件之一这表示可完成延迟操作执行
(1)发生异常,Leader副本发生了迁移,当前的代理不再是Leader副本
(2)发生异常,拉取消息的分区不存在
(3)日志段发生了切割,请求拉取的消息偏移量已不在活跃段内,同时Leader副本没有处在流处理的状态
(4)累积拉取的消息数已超过最小字节数限制
与DelayedProduce一样,DelayedFetch也需要实现tryComplete()方法和onComplete()方法,DelayedFetch的tryComplete()也用于检测DelayedFetch是否满足执行条件,若满足条件就调用forceComplete()方法执行延迟操作,与DelayedProduce不同的是,DelayedFetch并不要求本次订阅的分区都满足执行条件后才最终执行
DelayedFetch.onComplete()方法也是构造拉取返回结果回调responseCallback给客户端
(5)DelayedJoin
DelayedJoin是协助组协调器在消费组准备平衡操作时进行相应的处理,当消费组的状态转换为preparingRebalance时,即准备进行平衡操作,在组协调器的prepareRebalance()方法中会创建一个DelayedJoin对象,并交由DelayedOperationPurgatory负责监视管理
在消费组进行平衡操作时之所以需要DelayedJoin处理,是为了让组协调器等待当前消费组下所有的消费者都请求加入消费组,即发起了JoinGroupRequest请求,每次组协调器处理完JoinGroupRequest时都会检测DelayedJoin是否满足了完成执行的条件
DelayedJoin相应方法的实现是调用GroupCoordinator相关方法来完成,DelayedJoin.tryComplete()调用GroupCoordinator.tryCompleteJoin()方法,该方法判断是否还有未申请加入消费组的消费者,若所有消费者均已申请加入消费组,这表示DelayedJoin满足了完成执行的条件,否则继续等待,知道满足执行条件或超时,而DelayedJoin.onComplete()方法调用的是GroupCoordinator.onCompleteJoin()方法,onCompleteJoin()方法的主要执行逻辑如下
(1)若还有未加入消费组的成员,这将该成员相关信息从消费组列表移除
(2)若消费组的状态不为Dead,则先初始化与协调器对应的一个轮值标识generationId,然后根据该消费组下的成员列表是否为空分别做相应处理,若该消费组对应的元数据信息为空,这里利用kafka消息压缩清除的原理,当某消息的value为空时则表示将要删除同key的消息,组协调器通过这种方式将小辅助相应数据从kafka内部主题(“__consumer_offsets”)中清除,否则,遍历消费组下的每个成员构造JoinGroupResult,不过Leader消费者比Follower消费者多一个当前消费组的元数据信息字段,最后通过回调函数将JoinGroupResult发送给消费者,并对当前和下一次心跳检测做相应处理
(3)将第二步消费组元数据消息写入kafka内部主题,即在第二步若消费组下没有任何成员时,只是构造一条与消费组元数据信息相关的消息,该消息value为空,这样当经由本操作之后,会将该消费组在kafka内部主题保存的消息删除
DelayedJoin的功能及相应方法已介绍完毕,DelayedJoin.onExpiration()的方法也是调用GroupCoordinator.onExpirationJoin()方法,不过该方法没有做任何实现
(6)DelayedHeartbeat
DelayedHeartbeat用于协助消费者与组协调器心跳检测相关的延迟操作,DelayedHeartbeat相关功能的实现是调用GroupCoordinator的相应方法来完成的.
下面分别介绍DelayedHeartbeat相应方法的具体实现
DelayedHeartBeat.tryComplete()方法调用GroupCoordinator.tryCompleteHeartbeat()方法来检测是否满足执行条件,若满足一下条件之一这可触发执行
(1)member.awaitingJoinCallback不为空,其中member是指MemberMetadata,kafka将一个组协调器管理的成员元数据信息封装为一个MemberMetadata对象,成员的元数据信息包括心跳Session超时时间,上一次更新心跳的时间戳,成员所支持的协议(对于消费者是指分区分配策略),同时还包括组的状态信息等,wawitingJoinCallback不为空,这表示消费者已发出了JoinGroupReuqest,现在正在等待组协调器返回JoinGroupResponse
(2)member.awaitingSyncCallback不为空,表示正在进行SyncGroupRequest处理
(3)上一次更新心跳的时间戳与member.sessionTimeoutMs之和大于HeartbeatDeadline
(4)消费者已离开消费组
DelayedHeartbeat.onExpiration()方法调用的是GroupCoordinator.onExpireHeartbeat()方法,在该方法中检查tryComplete()方法执行条件的前3个条件是否都不满足,若均不满足时,这调用GroupCoordinator.onMemberFailure()方法进行处理,在OnMemberFailure()方法中首先会调用GroupMetadata.remove()方法将该消费者从消费组删除,然后根据GroupMetadata对应的消费组所处的状态进行相应处理.若消费组处于Dead或是Empty状态时,这不进行处理,若处于Stable或AwaitingSync状态,则将状态切换为PreparingRebalance,准备进行平衡操作;若是处于PreparingRebalance状态,则检测由于消费组的消费者减少是否满足了DelayedJoin执行条件尝试执行
DelayedHeartbeat.onComplete()方法调用的是GroupCoordinator.onCompleteHeartb()方法,但该方法没有做任何处理
(7)DelayedCreateTopics
在创建主题时,需要为主题的每个分区分配到Leader之后,才调用回调函数将创建主题结果返回给客户端,delayedCreateTopics延迟操作等待该主题的所有分区副本分配到Leader或是等待超时后调用回调函数返回给客户端
DelayedCreateTopic.tryCOmplete()方法用于检测延迟操作是否已满足执行条件,当检测到该主题的所有分区副本都分配到Leader后,LeaderDelayedCreateTopics即满足了执行条件
DelayedCreteTopics.onComplete()方法构造该主题与错误码映射关系,调用回调函数返回给客户端
DelayedCreateTopic.onExpiration()方法也是一个空实现,没有进行任何处理