1.定义训练方式
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy’])
2.开始训练
train_history = model.fit(x=train_Features,y=train_Label,validation_split=0.1,epochs=30,batch_size=30,verbose=2)
(1)输入训练数据的参数
x=train_Features,features共9个特征字段 y=train_Label label标签字段
(2)设置训练与验证数据的比例
设置参数 validation_split=0.1
(3)设置训练周期次数与每一批次的项数
epochs=30 执行30个训练周期 batch_size = 30 每个批次30项数据
(4)显示训练过程
verbose=2 Epoch 28/30 - 0s - loss: 0.4449 - acc: 0.8000 - val_loss: 0.4271 - val_acc: 0.8350 Epoch 29/30 - 0s - loss: 0.4456 - acc: 0.8011 - val_loss: 0.4335 - val_acc: 0.8252 Epoch 30/30 - 0s - loss: 0.4435 - acc: 0.8011 - val_loss: 0.4260 - val_acc: 0.8350
3.画出准确率的执行结果
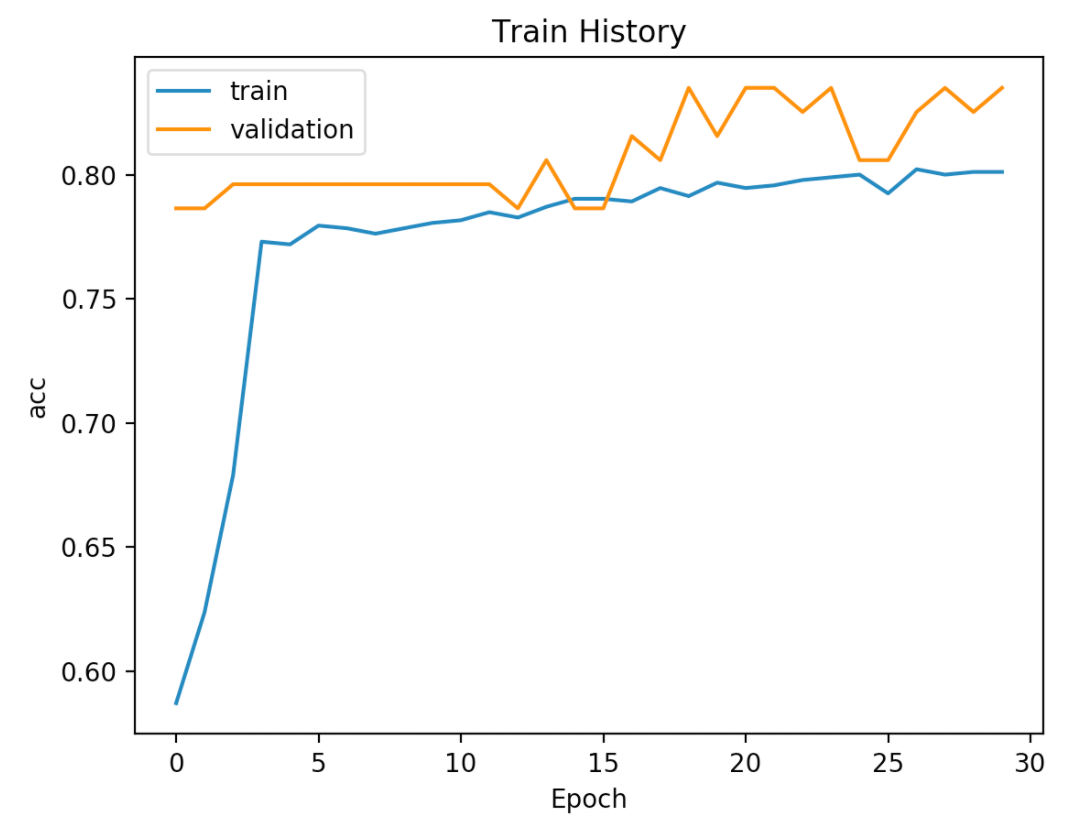
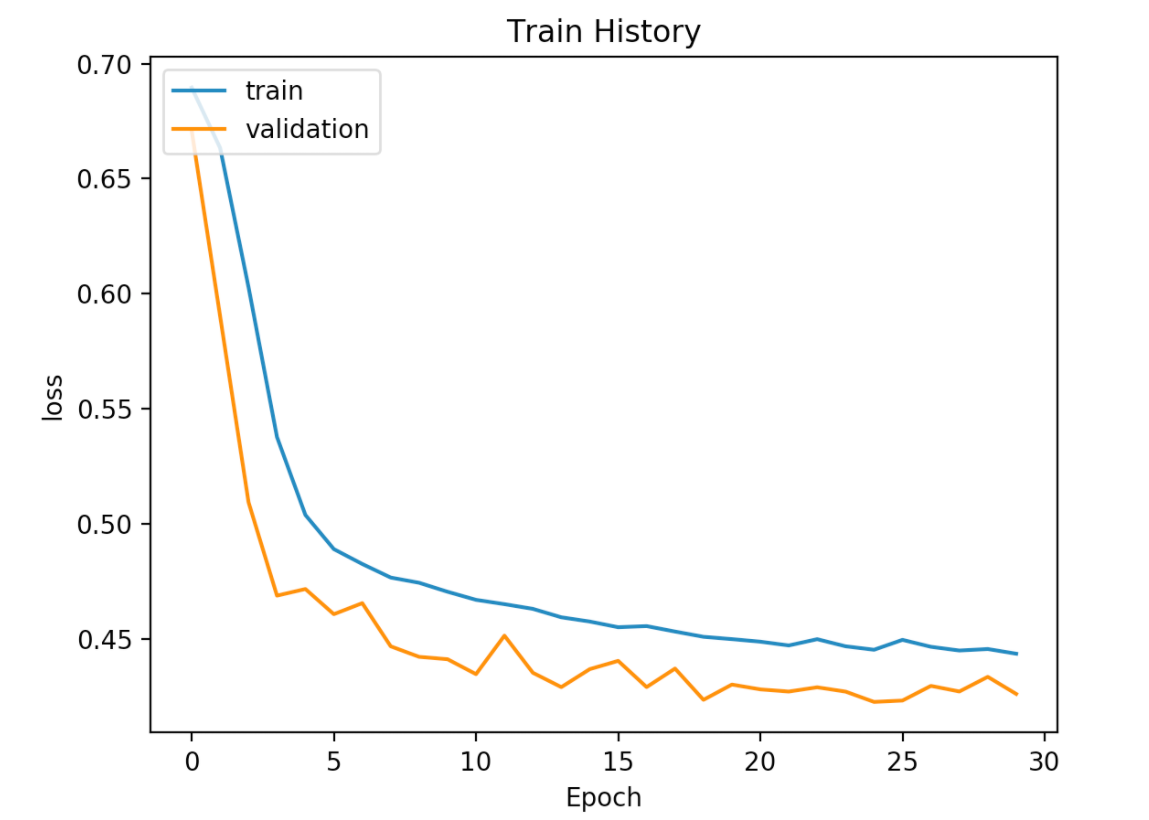
4.画出误差的执行结果
5.评估模型准确率
scores = model.evaluate(x=test_Features,y=test_Label) 32/244 [==>...........................] - ETA: 0s 244/244 [==============================] - 0s 25us/step 0.799180329823