当我们建立好深度学习模型之后,就可以使用反向传播算法进行训练。
1.定义训练方式
在训练模型之前,我们必须使用compile方法对训练模型进行设置:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
compile方法需输入3个参数,loss,optimizer,metrics
2.开始训练
train_history = model.fit(x_img_train_normalize, y_label_train_OneHot, validation_split=0.2, epochs=10, batch_size=128,verbose=1)
使用model.fit进行训练,训练过程会存储在train_history变量中,需输入下列参数:
(1)输入训练数据参数
x=x_img_train_normalize(图片特征值) y=y_label_train_OneHot(label照片图像真实值)
(2)设置训练与验证数据比例
设置参数validation_split=0.2
训练之前keras会自动将数据分成80%的训练数据和20%的验证数据。
(3)设置训练周期次数与每一批次项数
epochs=10 执行10个训练周期 batch_size=128 每一批次128项数据
(4)设置显示训练过程
verbose=2 显示训练过程
以上程序代码共执行了10个训练周期,每一个训练周期都执行下列功能:
使用40000项训练数据进行训练,分为每一批次128项,所以大约分为160批次(40000/10/128=313)进行训练
epoch(训练周期)训练完成后,会计算这个训练周期的准确率和误差,并且在train_history中新增一项数据记录
40000/40000 [==============================] - 181s 5ms/step - loss: 0.6230 - acc: 0.7801 - val_loss: 0.8211 - val_acc: 0.7245 Epoch 8/10 40000/40000 [==============================] - 184s 5ms/step - loss: 0.5571 - acc: 0.8046 - val_loss: 0.7855 - val_acc: 0.7357 Epoch 9/10
3.画出准确率执行的结果
下面是程序代码画出准确率执行的结果:
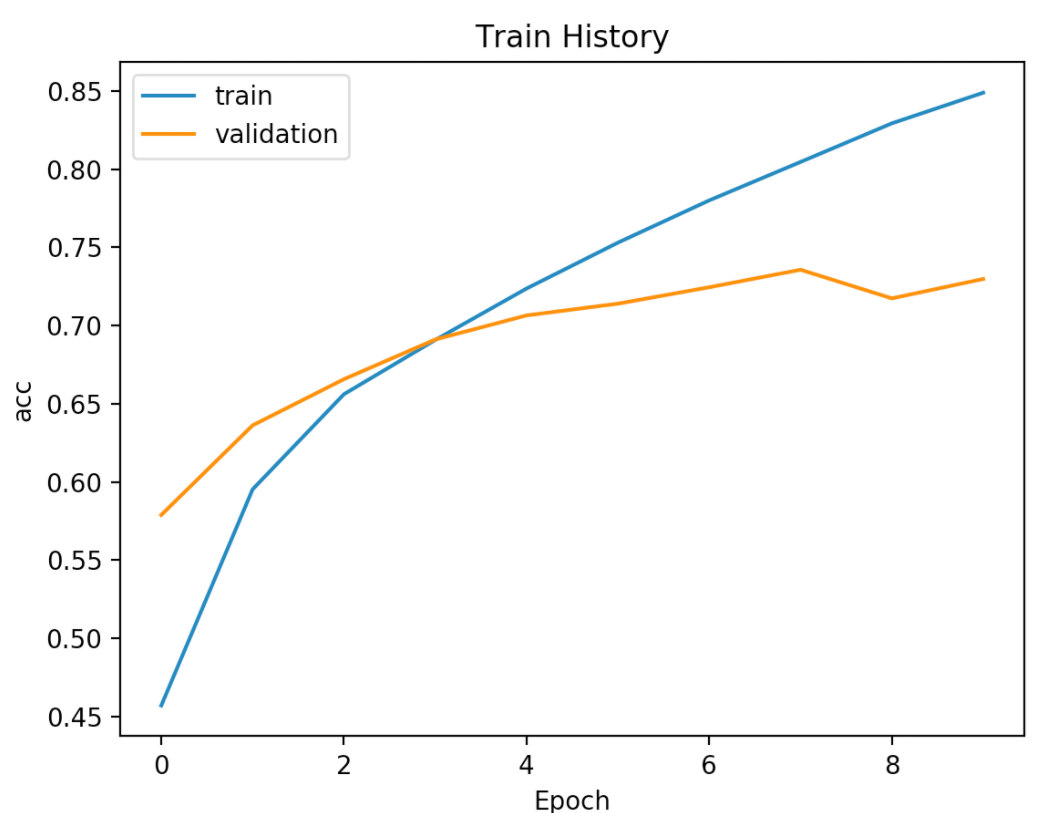
4.画出误差执行结果
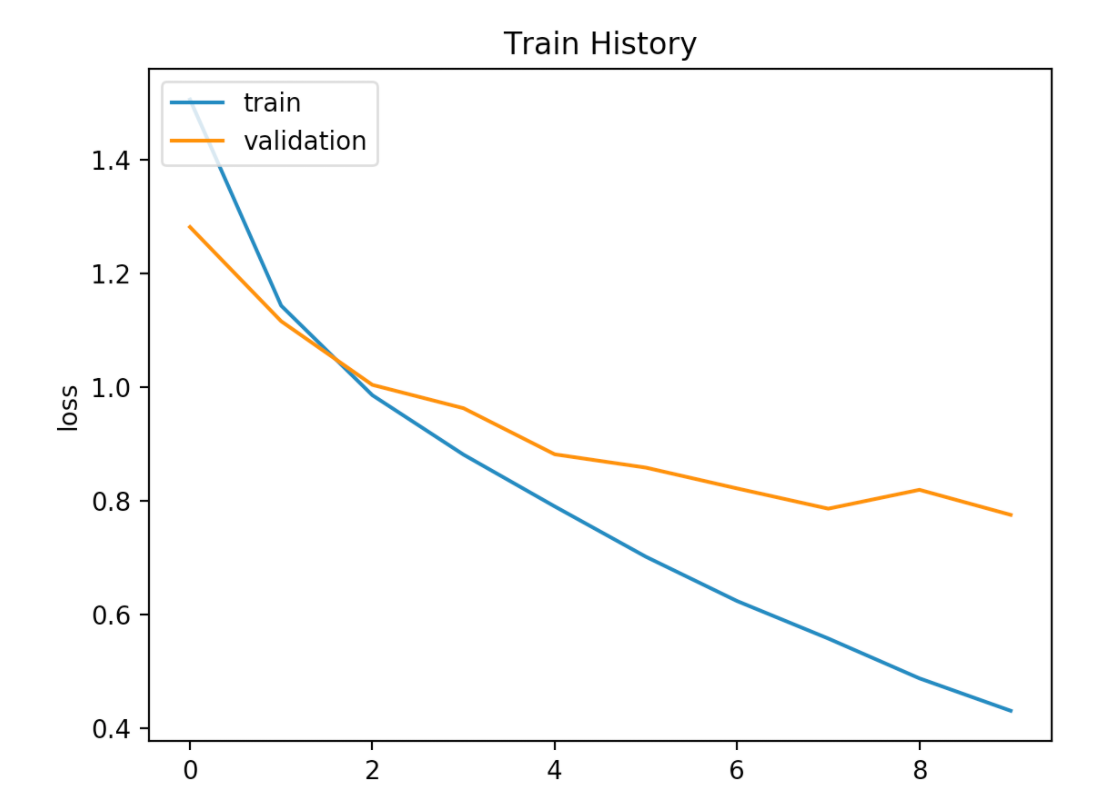
5.评估模型准确率
之前我们已经完成训练,现在要使用test测试数据集,评估模型准确率
scores = model.evaluate(x_img_test_normalize,y_label_test_OneHot,verbose=0) print(scores[1])
0.7293