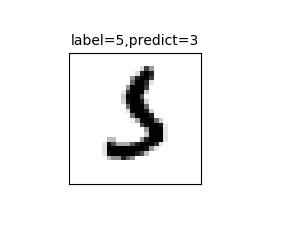
在上一节我们看到了一个预测错误:真实值是5,但是预测值是3.如果我们想要进一步指导在所建立的模型中哪些数字的预测准确率最高,哪些数字最容易混淆,就可以使用混淆矩阵(confusion matrix)来显示.
在机器学习领域,特别是统计分类问题,混淆矩阵也成为误差矩阵(error matrix),是一种特定的表格显示方式,可以让我们以可视化的方式勒戒有监督的学习算法的结果,看出算法模型是否混淆来两个类(将某一个标签混淆成来另一个标签)
1.使用pandas crosstab建立混淆矩阵
pandas提供来建立混淆矩阵的功能
print(pd.crosstab(y_test_label,prediction,rownames=[‘label’],colnames=[‘predict’]))
predict 0 1 2 3 4 5 6 7 8 9
label
0 970 0 0 0 0 2 4 1 3 0
1 0 1128 2 0 0 1 2 0 2 0
2 6 3 1001 3 1 0 3 4 11 0
3 0 0 0 1000 0 2 0 3 3 2
4 1 0 4 1 951 0 5 3 2 15
5 2 0 0 11 1 866 6 1 3 2
6 4 2 2 1 1 3 943 0 2 0
7 0 6 10 6 0 0 0 995 4 7
8 5 0 2 11 4 3 3 2 941 3
9 4 5 0 11 6 1 0 5 1 976
在以上混淆矩阵中,我们观察的结果如下:
对角线是预测正确的数字,我们发现:真实值1倍正确预测为1的项数有1128,预测准确率最高,最不容易混淆,真实值是5,倍正确预测成5的项数有866项最低,也就是说最容易混淆.
其他费对角线的数字代表将某一个标签预测错误,成为另一个标签,我们发现:真实值是5,预测值是3
2.建立真实值与预测DataFrame
因为我们希望能找出真实值是5,但预测值是3的数据,所以创建下列DataFrame,下面的程序代码用来创建DataFrame,包含label真实值与prediction(预测值)
df = pd.DataFrame({‘label’:y_test_label,’predict’:prediction})
print(df[:2])
label predict
0 7 7
1 2 2
以上执行的结果又两个字段,分别是label与predict
3.查询真实值是5但预测值是3的数据
pandas dataframe可以很方便的让我们查询数据,例如下面的程序代码,可以找出真实值是5,但预测值是3的数据
print(df[(df.label==5)&(df.predict==3)])
label predict
340 5 3
1003 5 3
1393 5 3
2035 5 3
2810 5 3
3117 5 3
3702 5 3
3968 5 3
4255 5 3
4355 5 3
5937 5 3
5972 5 3
5982 5 3
5985 5 3
4.查看第340项数据
我们可以查看第340项结果,真实值是5但预测值是3
plot_images_labels_prediction(X_test_image,y_test_label,prediction,idx=340,num=1)
从执行结果来看,这个数字图形看起来像5又像3,所以预测错误