TensorFlow中的降采样(subsampling)操作通过使用池化(pool)方法实现.该操作的基本思想就是同局部区域里面的一个值替代整个区域,常见的是max_pool和avg_pool两种方法.其中max_pool使用局部区域的最大值代替该区域所有元素,而avg_pool使用均值代替.
如图所示,你可以看到在一个16×16的矩阵上使用2×2的核,通过max_pool代替整个2×2区域
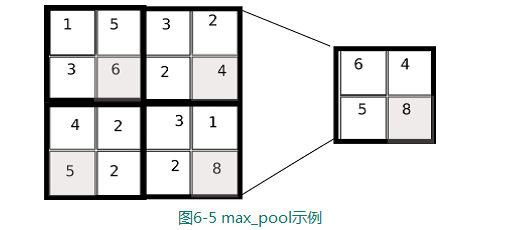
这种类型的池化操作也不是一成不变的,在LeCun的论文中,汇聚操作需要在原来的像素上乘上一个参数再加上一个偏差
1.降采样的属性
降采样的目标跟卷积层多少有些类似,他们都是降低信息的数量和复杂性的同时保存重要的信息的元素.降采样操作是对重要信息的一种压缩表示.
2.不变性
降采样层同样可以将一个复杂的信息简单化表示,通过滑动图像上的滤波器,我们将图像用更具有价值的部分表示,甚至能减少到大小为1的像素.相反的,该属性也让模型失去了位置性信息.
3.降采样的性能
降采样实现起来比较快,因为它大致上就是通过几组比较保留了一些信息,剔除了一些信息.
