本例中,我们会进入一个新的领域:解决非线性问题,该领域是神经网络附加值最大的领域.在开始该领域之前,我们会对几个汽车型号的燃料效率建模.该问题是输入多个变量,只有非线性模型才能取得比较好的结果.
(1)数据集描述和加载
对该问题,我们会分析一个著名的,标准的,数据组织得很好的数据集.我们有一个多变量的输入(有连续的,也有离散的),预测每加仑英里数(mpg)
这是一个玩具级的例子,但是这个例子会铺开通往更复杂问题的道路,而且该例子还有个好处,就是被大量研究过.
数据集由以下列组成
mpg:每加仑英里数,连续
cylinders:气缸,多值离散
displacement:排量,连续
horsepower:马力,连续
weight:车重,连续
acceleration:加速度,连续
model year:年份,多值离散
origin:产地,多值离散
car name:车名,字符串(不会使用)
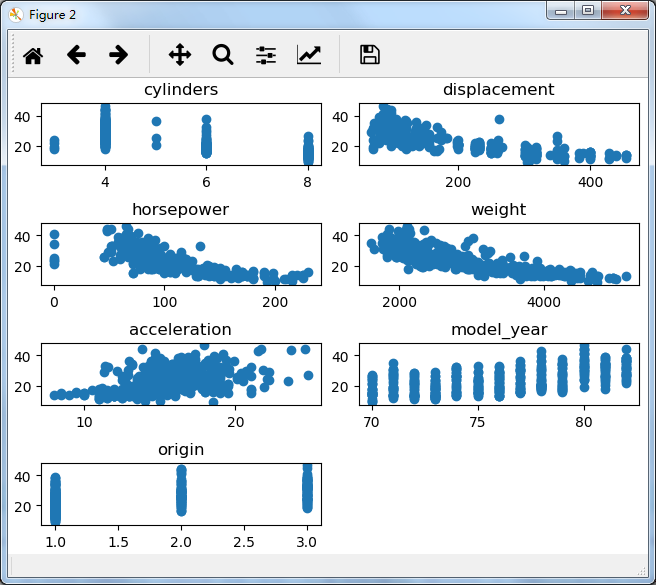
我们不会对该数据做详细分析,我们只是想看一下每一个连续的变量都跟目标变量的增减相关
(2)数据预处理
本例中,我们会使用一个前面描述的sklearn中的standardscaler对象:
# Scale the data for convergency optimization scaler = preprocessing.StandardScaler() # Set the transform parameters X_train = scaler.fit_transform(X_train)
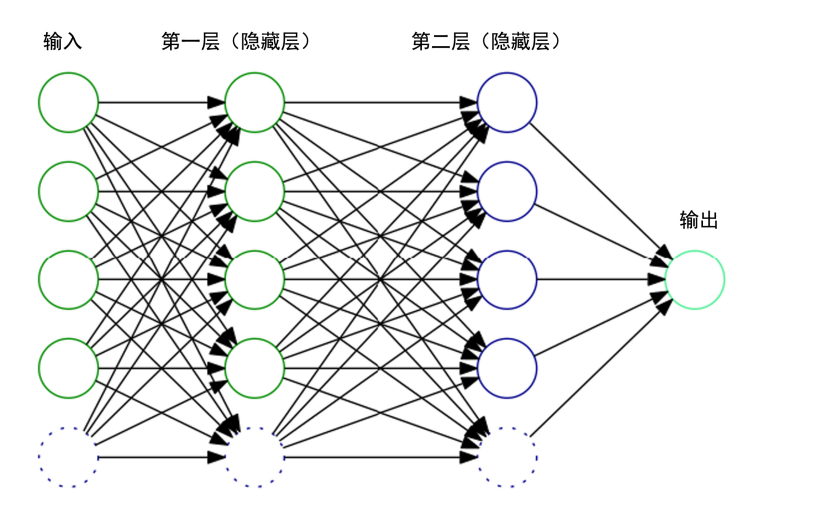
(3)模型架构
我们需要建立一个多变量输入,单变量输出的前向神经网络