1.基本概念
在正式使用和建立神经网络之前,我们需要学习以下神经网络的基本概念,这对于我们后面的学习非常有用.
(1)人工神经元
人工神经元就是使用一个数学函数来对生物的神经元建模
简单来说,一个人工神经元就是接收一个或多个输入(训练数据),对他们加和,并产生一个输出.一般来说,这里面的加和指的是加权求和(每个输入乘上权重,并加上一个偏差),然后将加和的输入传递给一个非线性函数(一般称为激活函数或者转移函数)
1))最简单的人工神经元–感知器
感知器是实现人工神经元最简单的方法,他的历史可以追溯到20世纪50年代,在20世纪60年代的时候,首次被发现.
简单来说,感知器就是一个二元分类函数,他将输入映射到一个二元输出,如图所示:
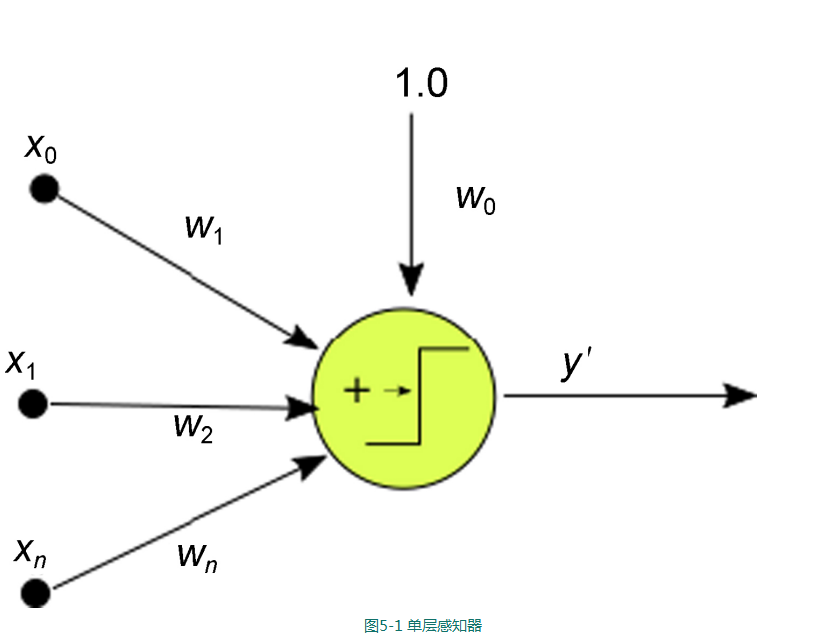
2))感知器算法
简化版的感知器算法如下:
以一个随机分布初始化权重和偏差(通常比较小)
选择一个输入向量,并将其放入神经网络中;
将输入和权重相乘,并加上偏差,计算网络的输出y`
感知器的函数如下

如果y’≠y,将权重wi加上△w=yx
返回第二步
2))神经网络层
我们可以对单层的感知器进行泛华,将他们堆积起来,并互相连接,如图所示.但这就带来一个问题,这样的线性组合出来的模型还只是一个线性分类器,对于复杂的非线性分类,这种方式并不能正确拟合,这个问题需要激活函数来解决.
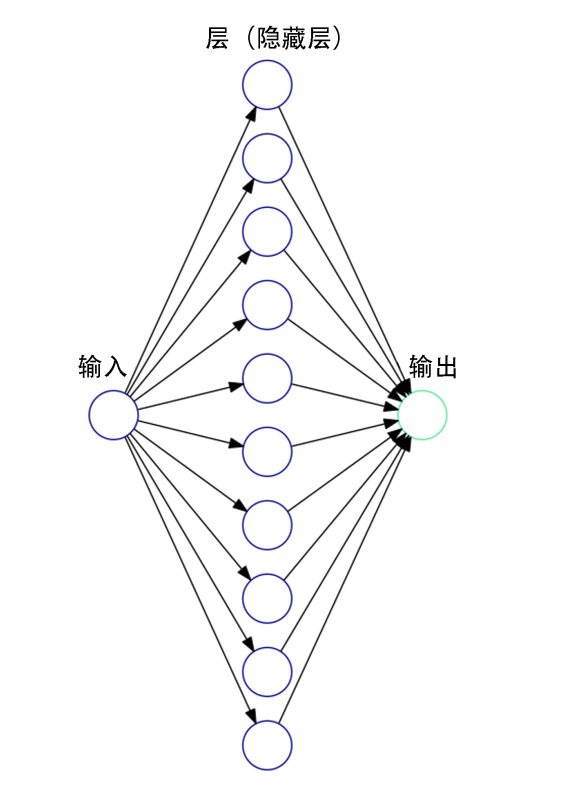
1))神经网络激活函数
单独的单变量线性分类器并不能带来神经网络的强悍性能,就算那些不是很复杂的机器学习问题都会涉及多变量和非线性,所以我们常常要用其他的转移函数来替代感知器中原本的转移函数.
logidtic:典型的激活函数,在计算分类的概率时非常有用
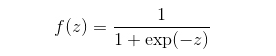
tanh:跟sigmoid函数很像,但是范围是-1,1,而不是0,1
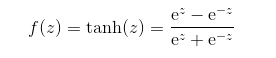
relu:修正线性函数,该函数主要是为了对抗梯度消失,也就是当梯度反向传播到第一层的时候,梯度容易趋近于0或者一个极小值
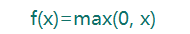
在我们计算总的误差的时候,因为是一整个函数作用于输入数据,所以我们要调整这个方程中的所有变量,来最小化方程.
怎样最小化误差呢?正如我们在优化部分所学,我们通过损失函数的梯度来最小化误差.
如果我们的网络拥有多层权重和转义函数,我们最终需要通过链式法则也求导所有参数的梯度.
2))梯度和反向传播算法
在感知器的学习阶段,我们按照每个权重对误差的”责任”,按比例调整权重
在更复杂的网络中,误差的责任被分散在整个结构的所有操作之中.
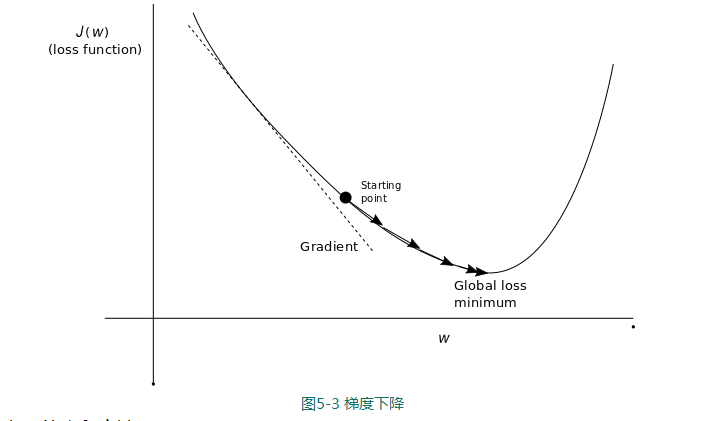
3))最小化损失函数:梯度下降
我们由下图理解下损失函数
4))神经网络的选择-分类VS回归
神经网络既可以被用于回归问题,也可以被用于分类问题.不同的地方在于结构的最后一层.如果需要的结果是一个数值,那么就不要连接标准函数,如sigmoid.如果是这样的话,我们得到的就是一个连续值.
3.有用的库和方法
本章中我们会用到TensorFlow中的一些新的函数,下面是我们需要的最重要的函数
(1)TensorFlow激活函数
最常用的激活函数如下:
tf.sigmoid(x):标准的sigmoid函数;
tf.tanh(x)双曲正切函数;
tf.relu(x)修正线函数
TensorFlow中其他的函数
tf.nn.elu(x) 指数线性单元;如果输入小于0,返回exp(x)-1,否则返回x
tf.softsign(x) 返回x/(abs(x)+1)
tf.nn.bias_add(value,bias):增加一个bias到value
(2)TensorFlow中损失优化方法
tf.train.gradientDescentOptimizer():原始梯度下降方法,唯一参数就是学习率
tf.train.adagradOptimizer:自适应调整学习率,累加历史梯度的平方,做为分母,防止有些方向的梯度值过大,提高优化效率,善于处理稀疏梯度
tf.train.adadeltaoptimizer:扩展adaGrad优化方法,只累加最近的梯度值,而不对整个历史上的梯度值进行累加
tf.train.adamoptimizer.train.adamoptimizer():梯度的一阶距估计和二阶距估计动态调整每个参数的 学习率.
(3)sklearn预处理函数
我们看一些sklearn数据预处理函数:
preprocessing.StandardScaler():数据正规化是机器学习估计的一个常见要求,为了模型能更好的收敛,我们通常会将数据集预处理到一个零均值单位方差的高斯状分布.通常,我们会将数据的各个纬度都减去他的均值,然后乘以一个非零的数.这个非零的数就是数据集的标准差.对于该任务,我们直接使用standardScaler,他已经实现了我们上面提到的操作,他也保留了变换操作,让我们可以直接用在测试集上.
standardscaler.fit_transform():将数据调整到所需要的形式.standardScaler对象会存储数据变化的变量,这样我们可以把数据解正规化到原始格式
cross_validation.train_test_split:该方法能够将数据集分割成训练集和测试集,我们只需要提供两者的比例,该方法能够自动帮我们处理